6 Step Framework for Marketing Content Optimization
In today’s marketing landscape of channel proliferation, ultra-savvy buyers, and chronic shortages of time and attention, investing in really good content might be the highest ROI decision a CMO or CRO can make. Really good content performs in a non-linear way, but what is it that makes that “one piece” drive ten times more eyeballs than that other piece? In retrospect, looking at great content, it might seem obvious, but if it were truly obvious, then why aren’t all the content pieces written that way to begin with?
So what is a CMO to do? Is there a systematic way for content optimization, aligned to buyer and influencer interest, that evolves in an agile way? In this blog post, I present a framework for creating a content factory based on both data and creativity. This is the framework we use at MarketBridge for our clients, and it works really well. It’s not software, and it is by no means hands-off, but it is a systematic method for content optimization.
The key is combining analytics and human intelligence in a process, connecting living feedback loops from one into the other and back again. Managed effectively, a fact and art based content factory like this can create, manage, and target content for high ROI in a predictable, measurable way. This blog post discusses content built for a complex, considered purchase decision, which is primarily text-based, but it can be evolved to work for both video content and pithier graphic pieces.
There are six key steps, as outlined in the diagram below. Note the horizontal line; above the line, a data-driven, machine-learning approach optimizes content, and below the line, creative minds take over.
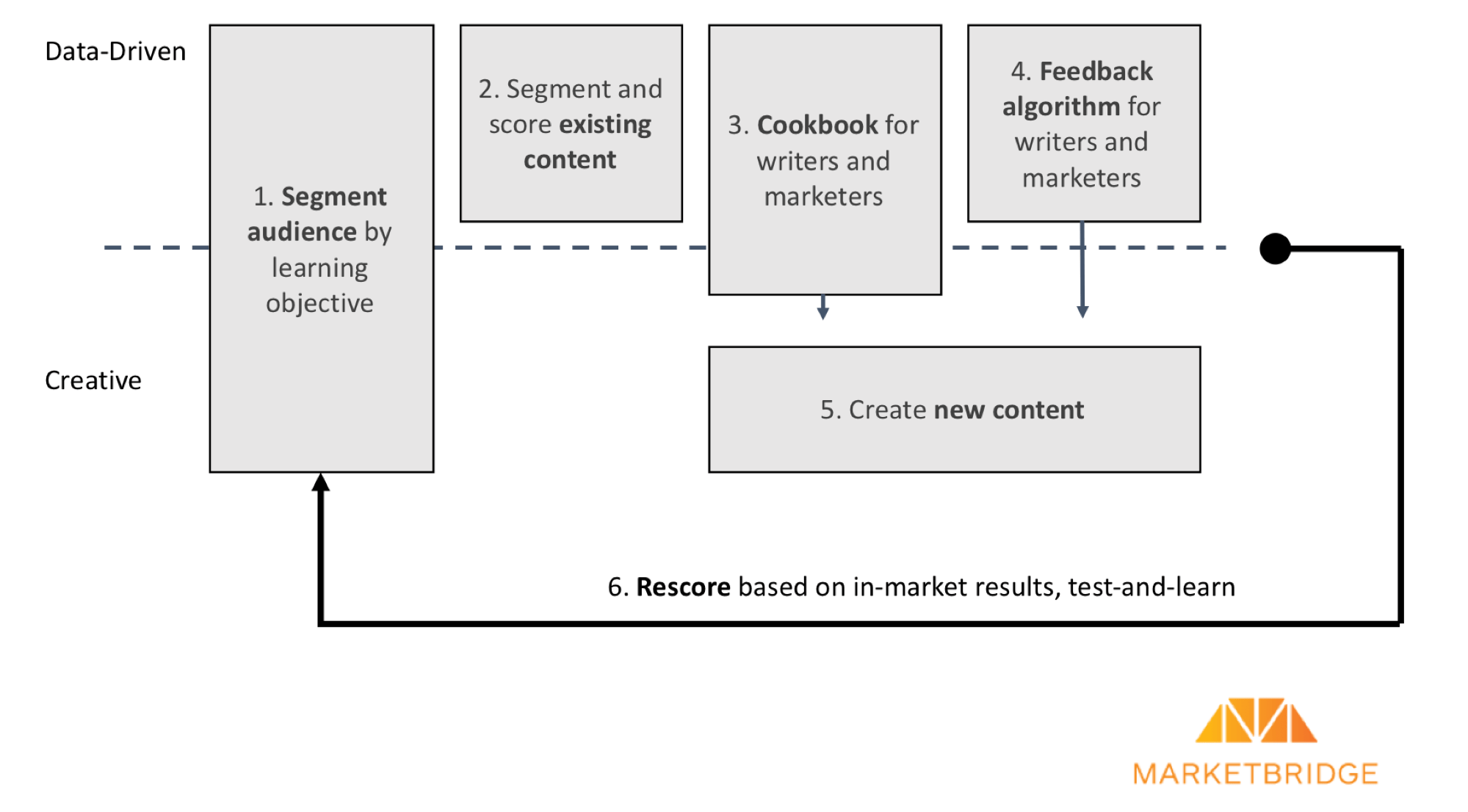
1) Segment Your Audience by Learning Objective
The marketer today knows a tremendous amount about his or her audience. Each entry in the CRM database carries with it personal information, firmographic information (if B2B), and stimulus-response information. All of this information provides practically infinite segmentation potential for content optimization. So what does a good content segmentation look like? A good content segmentation should be based on the learning goal of the individual.
MarketBridge research shows that in 2018, considered purchase buyers are really just learners that companies intercept in their quest for knowledge. It’s now possible, for example, for a head of database marketing to learn a ton about machine learning in Python without ever enrolling in a university program, or spending a cent on proprietary software. When a good manager or executive is faced with a problem, they try to learn all they can about the problem, not immediately call a vendor.
Concretely, a software company might sell a product for insurance risk assessment. The buying entity (firm) is an insurance company, but what about learning objectives? Primary research might show that there are four primary learners in the company, along with learning objectives:
Learner Segmentation
| Learner | Learning Goal |
| Technical | How can I future-proof my company with new technologies? |
| Underwriting | How can I innovate and create better risk prediction algorithms? |
| Financial | What steps can I take to mitigate risk to impact my product’s bottom line? |
| Product | How can I launch new products with better risk profiles? |
It’s important to note that to do this step correctly, primary quantitative research is necessary. In quantitative research, it’s key to operationalize these segments with knowable data (data available for each lead/contact in the marketing/sales database) to be able to target actual content when the time comes. This can be done with a classifier algorithm.
There are many best practices for doing truly insightful, actionable “learning objective” research for content optimization, but these are out of scope for this blog post. I’ll try to do another post in the future on how specifically to conduct the research.
2) Segment and Score Existing Content
After segmenting buyers, it’s necessary to do the same with content. In most companies, existing content contains a treasure trove of insights. Text mining of documents using modern open source frameworks, combined with binary outcome data, provides a powerful tool for content optimization. The basic idea is simple: Understand the unique attributes of successful content for specific segments.
The key to this step is that we aren’t just interested in providing a probability score for each piece of content aligned against each segment. That’s great, but we want to go one step further and provide insight to the content creators on how to make future content better. Thus, opaque models like neural networks aren’t really appropriate here.
One highly recommended step to make a predictive content model consumable by humans is variable reduction inside of each document. It’s impossible to make a model understandable with sparsely populated variables like words. Words and phrases should be grouped thematically across the entire collection of documents. This is an unsupervised machine learning task, typically using a technique like principal components analysis (PCA). Concretely, we might end up with five thematic groupings (although in practice the number of these components will be much higher):
| Component | Key Terms |
| Integration | API, RESTful, loosely-coupled, JSON… |
| Risk Algorithm | Logistic regression, survivor models, age bands… |
| ROI | ROI, profit, customer lifetime value, acquisition… |
| Case Studies | Results, company, individual, brokerage… |
| Differentiation | Competitive, [Competitors]… |
| Etc… | …Typically 10-25 |
Once this is done, each document can then be scored against these describable, knowable components, and then an understandable model can be provided back to both content writers and the marketers who are responsible for getting them to the right audiences. All of this information can be used for content optimization.
Other factors can also be brought to bear in the scoring process, other than just the overall appropriateness of the content. For example, a time element of the buying cycle can be added (cold lead / prospect / qualified lead / opportunity / final negotiation) resulting in several different “scenario” models for each piece of content.
3) Cookbook for Writers, Marketers, and Sales People
Once the model has been created, it’s key to make it truly consumable (readable) by marketers and writers. This is one thing that MarketBridge has realized is missing in the analytics space — humans really need analytics, but a lot of the time, the analytics provided are a black box. Humans are less likely to trust something they don’t understand. In the case of a sales rep, this just means they are likely to say, “I’ll go back to using my intuition.”
The components of the cookbook might include:
- A persona of each learner, describing them, their job, what they are looking for, and how to find them using knowable data
- A description of the principal components of the content repository, including plain English descriptions of what they mean, and examples of documents or specific sections of documents that typify each
- How each learner prioritizes the components
- Examples of excellent existing documents that appealed well to each learner, and why
- Key components that are conspicuously missing from the existing corpus of documents (places to focus on future content creation)
This cookbook provides the glue between the analytics team, the content creators, and the marketers. It’s also important to note that the cookbook must be evergreen, in other words, updates constantly with new feedback.
Using this cookbook, content creators can now apply their art to the facts, creating new content that is targeted and pre-optimized. Likewise, salespeople and marketing practitioners will better understand why “this specific piece of content” is great for this buyer, and will be less likely to not use it because they trust their intuition more.
4) Feedback Algorithm for Writers
Using machine learning, data scientists can also give writers a real-time tool to improve their writing. A tool like this ingests the document as raw text and then scores its likely appeal to each segment. On top of this, the tool provides specific reasons as to why the document has an appeal or doesn’t, using the components outlined above.
Concretely, feedback might look like this (with a lot more detail):
| Learner | Learner Score |
| Technical | 74 |
| Underwriting | 6 |
| Financial | 9 |
| Product | 21 |
| Component | Score | Positive Terms | Missing Terms |
| Integration | 77 | API, RESTful… | Loosely coupled… |
| Risk Algorithm | 12 | Age | Band, survivor, death, risk… |
| ROI | 17 | Profit, cost | ROI, margin,… |
| Case Studies | 43 | MassMutual, Brokerage X | [All other companies] |
| Differentiation | 55 | Competitor A | Competitor B, C, D |
| Etc… |
A tool like this can be used multiple times throughout the writing process for content optimization. I’m not suggesting that a tool like this in any way replaces the creativity of the writer, but it can better link facts and analytics to the writing process, while at the same time exposing blind spots that might otherwise be missed.
When building this kind of tool, work with the writers and marketers to make sure that the output is understandable and actionable. Essentially, the data science team is creating a mini product here for the marketing department. Watch them write and use the tool, and see how they use (or don’t use) the scoring outputs.
5) Create New Content
Once the factory is running, it’s important to remember to use the shotgun as well as the rifle. A rifle approach optimizes for content effectiveness based on what was learned from previous iterations of content. This is a great, data-driven approach for optimizing ROI. A shotgun approach, on the other hand, adds new, diverse information—in this case, new content—and adds this new information into the model. Another way to think about the shotgun approach is purposely adding creativity back into the model.
This is where creative marketers and content writers come into play. Gaps in content among the “training set” can be identified by data scientists, and these gaps can be addressed by writers and content creators—the “shotgun.” It is this creative process of content optimization that truly allows the model to learn and grow.
6) Rescore Based on In-Market Results
Finally, the loop is closed by refreshing the models and consumable analytical elements—content scoring, the feedback algorithm, and the cookbook—based on new content and new campaigns. The creativity of the content creators is used to expand the scope of the content model, and ultimately to drive better performance. In this way, the creative people are linked fully with the data people—and facts and art come together to drive content optimization. Done correctly, a “learning organization” forms, driving continuous improvement in marketing performance.
Overall content effectiveness can be measured with simple dashboards in a time series (overall open rate by segment and by stage, for example), showing how modeling and creativity are driving improvements over time (or not.)
Conclusion
A hybrid analytical-creative content optimization factory is a proven method for creating effective content. This methodology fits into a larger theme of combining human creativity with rigorous data-driven techniques.
Postscript: Out of Scope
There’s a lot that this blog post glosses over, including the specific modeling libraries and steps to use for both unstructured content segmentation, and for supervised classification of existing content. It also only deals with text, and doesn’t get into content attributes like format, video / audio, or channel. I also don’t talk at all about how to do “learning objective” primary research, which I promise I will get back to.